Details about river forcing files#
We use the dataretrieval-python package to access USGS NWIS river data.
Background information#
There is a report from the Coast Survey Development Laboratory modeling group’s development of the CIOFS model, and this along with two nowcast rivers forcing files we received from the NOAA OFS modeling group is what we used to create our own river forcing files, trying to follow the same logic when possible.
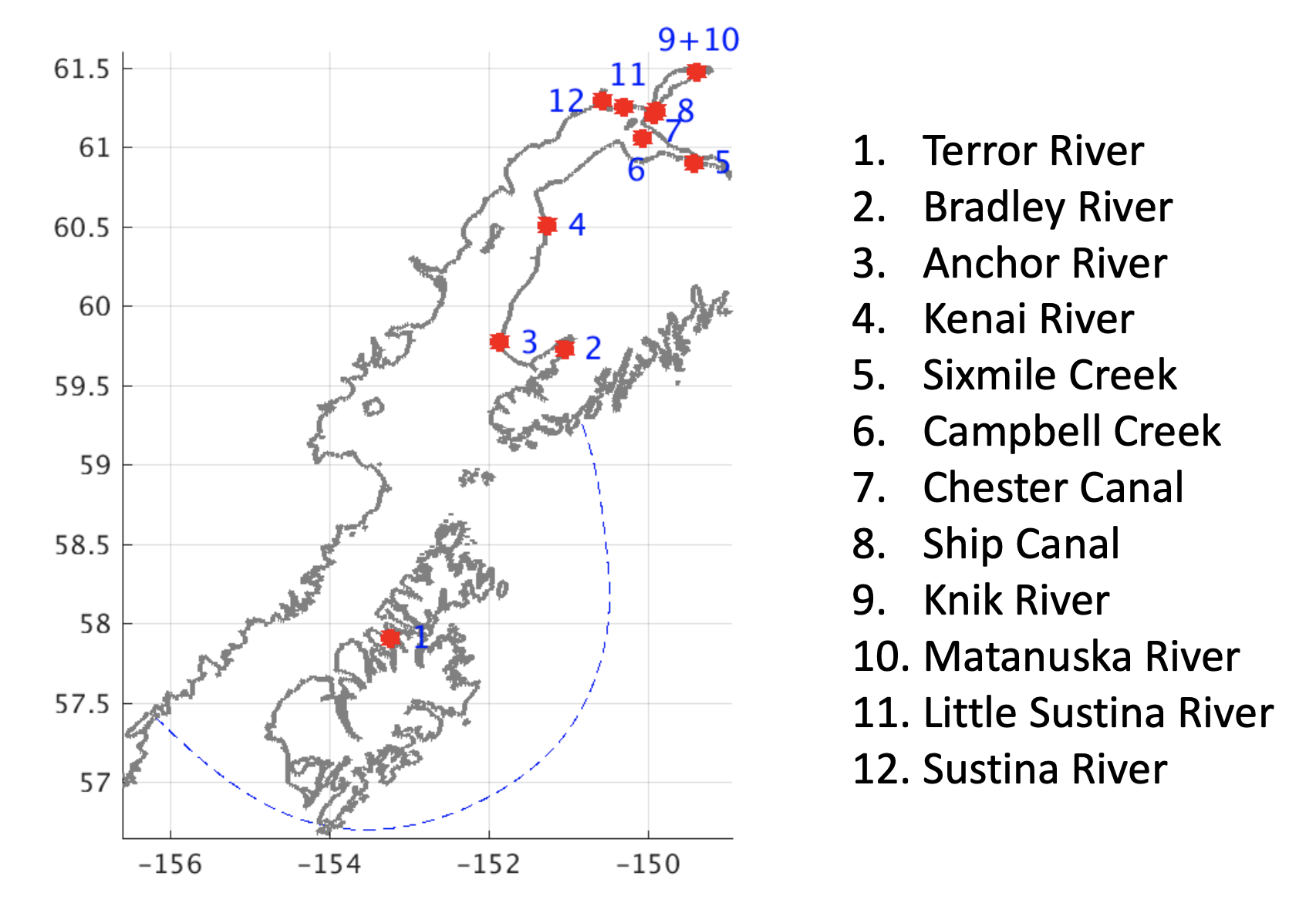
Freshwater is included in the CIOFS model as 12 rivers spread over 36 river points. The rivers included are listed in the left column here:
Number |
River Station in Model |
USGS Station Used: Discharge |
USGS Station Used: Water temp |
Notes |
|---|---|---|---|---|
1 |
15295700: |
15295700 |
15295700 |
|
2 |
15239070: |
15239070 |
15239070 |
|
3 |
15239900: |
15239900 |
15239900 |
|
4 |
15266300: |
15266300 |
15266300 |
|
5 |
15271000: |
15271000 |
15258000: |
|
6 |
15274600: |
15274600 |
15276000: |
|
7 |
15275100: |
15275100 |
15276000: |
|
8 |
15276000: |
15276000 |
15276000 |
|
9 |
15281000: |
15281000 |
15284000: |
|
10 |
15284000: |
15284000 |
15284000 |
|
11 |
15290000: |
15290000 |
15290000 |
|
12 |
15292780: |
15292000: |
15292780 |
Discharge from 15292000 is multiplied by 2. |
We followed what we saw in two river forcing files from the CIOFS group, and ascertained some details to include in the data processing:
River salinity is set to 0.005 for all rivers
River temperature is never allowed below 1 degree Celsius.
Use all data in UTC.
River input locations are shown on this map from the development report:
General approach#
This is a text flow chart of the logic in create_river_roms.py. Logic flows first down, then across a line and stops if “Done”, otherwise continues down the list. No gage data is used in this analysis.
Discharge#
get discharge data.
Check for:
empty → Use mean time series
fully present (all time stamps for date range) with good data flags (“A” or “P” flag) → use, done.
Reindex to fill all missing times with nans
Deal with other flags (ice or equipment malfunction): fill all with nan (“A, e” or “P, e” flags are ok)
Check gap lengths.
Has gaps in data. Process all gaps. If gaps are:
Less than 7 days → interpolate
Over 7 days → Use mean time series.
Water temperature#
get temp data.
Check for:
empty → use mean data. Done.
fully present (all time stamps for date range) with good data flags (“A” or “P” flag) → use, done.
Reindex to fill all missing times with nans
Check gap lengths.
Has gaps in data. Process all gaps. If gaps are:
Less than 8 days → interpolate
Over 8 days → use mean data
More details#
Station substitutes are listed in the Station Table above. There is one station substitute for discharge, and more for water temperature.
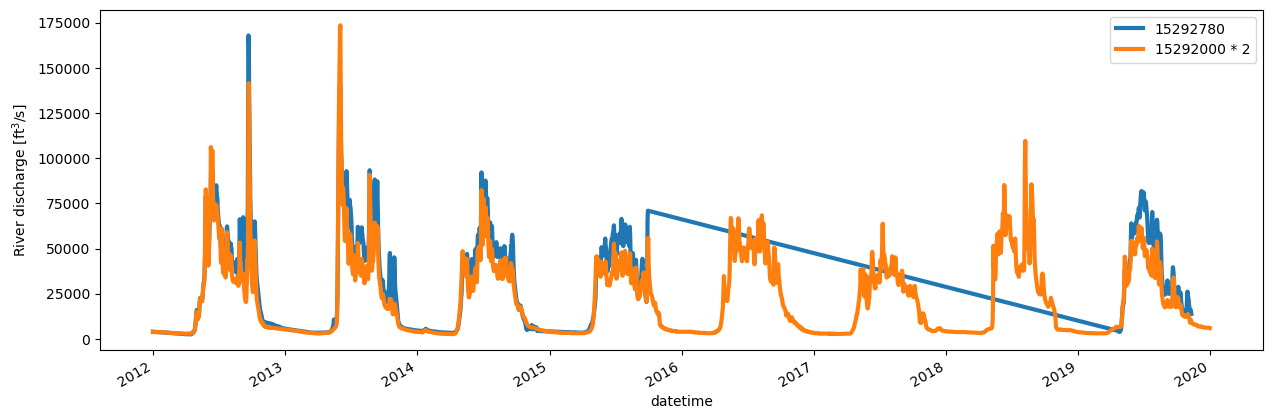
The model development report stated that because the desired Station 15292780 is not available for a long time, they substituted discharge from Station 15292000 and multiplied by 2 to approximate the difference seen between the two stations.
The model development report stated that temperatures from Bradley River (Station 15292780) were used for all stations. We decided to allow the water temperature to vary in space.
We use mean time series for water temperature and discharge when real-time data is not available.
Details for each point are below.
Discharge for Station 15292780#
The NOAA Report states that they used Station 15292000 discharge multiplied by 2 to replace discharge from Station 15292780 since Station 15292780 has a relatively short lifespan. We do the same in our simulations. Here is the comparison of the daily means for these two time series, including the multiplication factor. The match is reasonable.
Show code cell source
station = "15292780"
start = "2012-1-1"
end = "2020-12-31"
df1 = nwis.get_record(sites=station, service='dv', start=start, end=end)
station = "15292000"
df2 = nwis.get_record(sites=station, service='dv', start=start, end=end)
ax = df1["00060_Mean"].loc[:"2019"].plot(figsize=(15,5), label="15292780", lw=3)
(df2["00060_Mean"]*2).loc[:"2019"].plot(ax=ax, label="15292000 * 2", lw=3)
plt.legend()
plt.ylabel("River discharge [ft$^3$/s]");
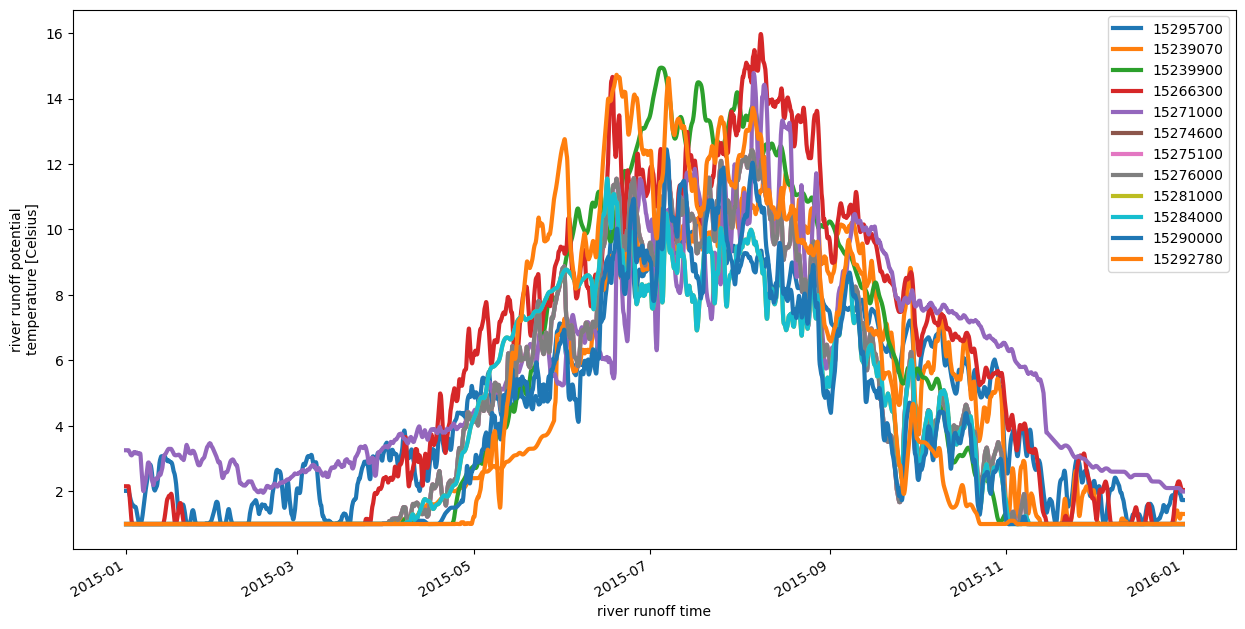
Geographic variation of water temperature#
The development report states that Bradley River (15239070) was used to represent all rivers in the model. We chose to allow for spatially-varying data. This one year of data shows an example of the variation in temperature data across the region. There is a fair amount of variation, but we have run no tests to analyze how impactful the variation is for the final results.
Show code cell source
year = 2015
loc = f"{chr.PATH_OUTPUTS_RIVER}/axiom.ciofs.river.20150101.nc"
ds = xr.open_dataset(loc)#, concat_dim="time", combine='nested', engine="netcdf4")
ds = ds.swap_dims({"time": "river_time"})
unique_inds = list(set([station_list_file.index(station_list_file[i]) for i in range(nrivers)]))
labels = [station_list_file[i] for i in unique_inds]
ds["river_temp"].isel(s_rho=0, river=unique_inds).plot.line(x="river_time", lw=3, figsize=(15,7));
plt.legend(labels);
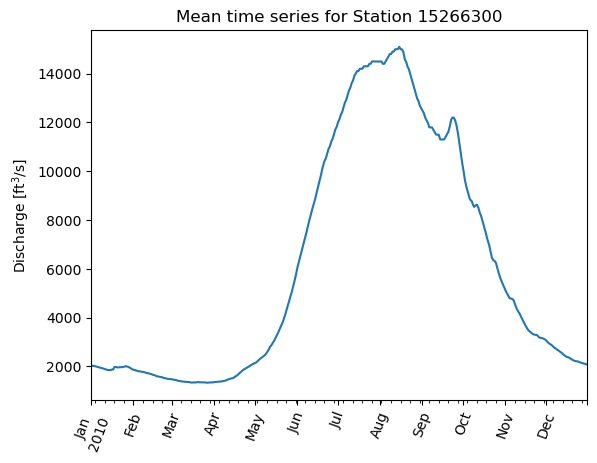
Mean time series#
Show code cell source
station = "15266300"
# start and end are for returning the desired window of values, not for computing the mean time series
start, end = "2010-1-1T00:00", "2010-12-31T00:00"
df = find_mean_time_series(station, start, end, "00060")
df.plot(rot=70)
plt.ylabel("Discharge [ft$^3$/s]")
plt.title(f"Mean time series for Station {station}");
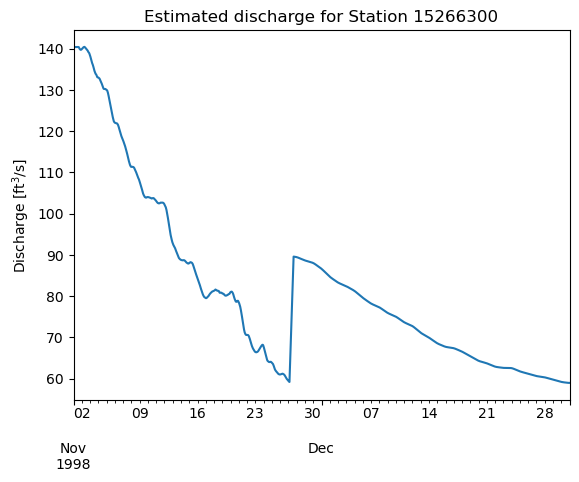
The impact of substituting the mean time series data in for the discharge when needed is that there could be a jump between the two signals. We simply perform a 12 hour rolling mean on the discharge signal at the end of processing in order to improve this, but it is a small measure; there will still be some unrealistic jumps in the river signals. However, we think it is worth it to have more freshwater entering the model domain when we know it is present and important to the region.
Show code cell source
start, end = "1998-11-01T00:00", "1998-12-31T00:00"
station = "15266300"
df = find_discharge(station, start, end, ndays=8)
df.plot()
plt.ylabel("Discharge [ft$^3$/s]")
plt.title(f"Estimated discharge for Station {station}");
Comparing Axiom and NOAA versions of two river forcing files#
We received two example nowcast river forcing files which we recreate here as a comparison with our methods. Note that in order to compare with the four-day nowcast files we do two things differently from our month-long hindcast forcing files:
interpolate under 2 days and use gage or mean time series data over 2 days instead of 8 days for both
do not apply a rolling mean of 12 hours
The main differences seen below are:
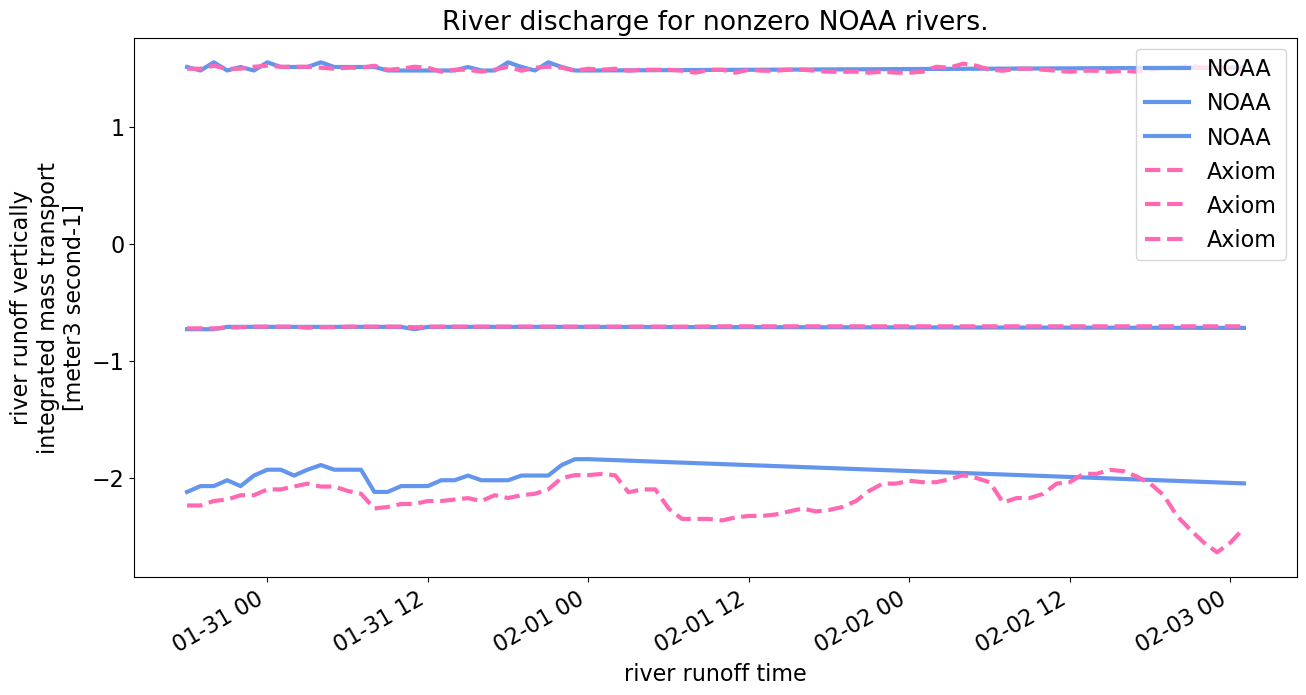
We do not estimate discharge from gage data, but we do include discharge from the statistical mean time series for the station if there are any iced or equipment malfunction flags. Because of this, we include much more freshwater input as compared with the example files. NOAA’s file does include an estimate of discharge from gage data from one river, but not from other rivers.
We used geographically-varying water temperature data, whereas the NOAA groups use data only from Bradley River (Station 15239070). When real-time water temperature data is not available, we use the statistical mean time series for the station. When a station has never had an instrument to measure water data, we have a replacement station as shown in the station table.
The nowcast forcing files are created by NOAA at the mid point of the time series such that they use the real-time data up until the start of the simulation, and the second half of the forcing is a simple linear extrapolation of the available data (which is why they appear as straight lines for those times).
Show code cell content
def plot_comparison(ds, dscompare):
plt.rc('font', size=16)
color_noaa = "cornflowerblue"
color_axiom = "hotpink"
kwargs_line = {"x": "river_time", "lw": 3}
kwargs_noaa = {"color": color_noaa, "label": "NOAA"}
kwargs_axiom = {"color": color_axiom, "label": "Axiom", "ls": "--"}
fig, axes = plt.subplots(1, 3, figsize=(15,5))
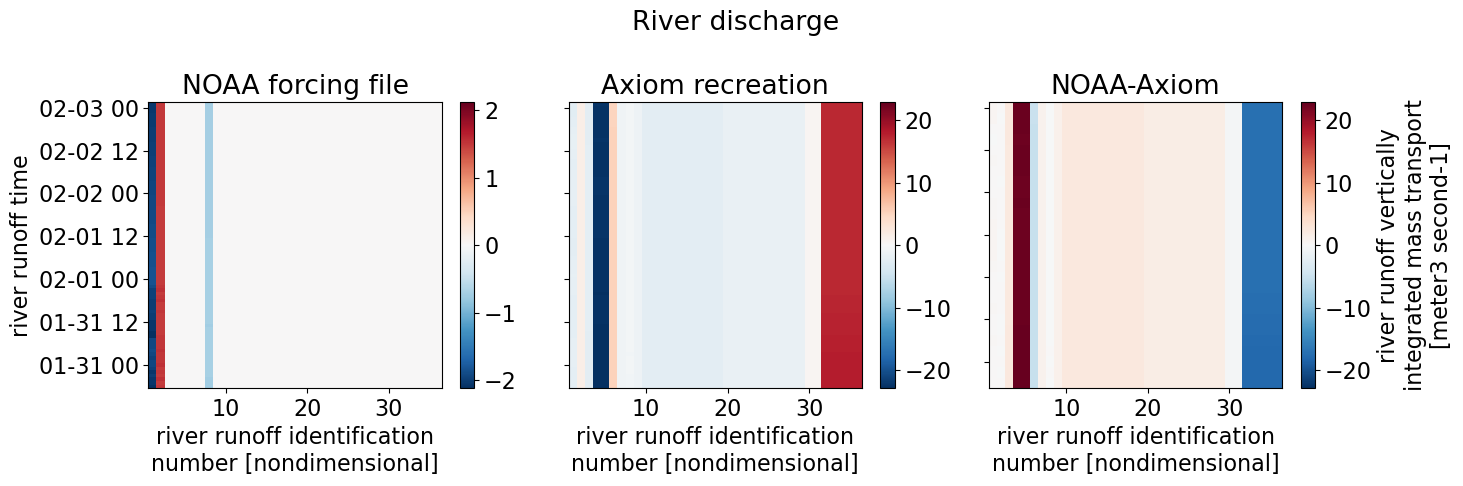
ds["river_transport"].plot(ax=axes[0], cbar_kwargs={"label": ""})
dscompare["river_transport"].plot(ax=axes[1], cbar_kwargs={"label": ""})
(ds["river_transport"] - dscompare["river_transport"]).plot(ax=axes[2])
axes[0].set_title("NOAA forcing file")
axes[1].set_title("Axiom recreation")
axes[1].set_ylabel("")
axes[1].set_yticklabels("")
axes[2].set_title("NOAA-Axiom")
axes[2].set_ylabel("")
axes[2].set_yticklabels("")
fig.suptitle("River discharge")
plt.tight_layout()
noaa_discharge = round(float(abs(ds['river_transport']).sum()*3600/1000**3), 3) # m^3/s * 3600 s for hour * (1km/1000m)^3
axiom_discharge = round(float(abs(dscompare['river_transport']).sum()*3600/1000**3), 3) # m^3/s * 3600 s for hour
unique_inds = list(set([station_list_file.index(station_list_file[i]) for i in range(nrivers)]))
labels = [station_list_file[i] for i in unique_inds]
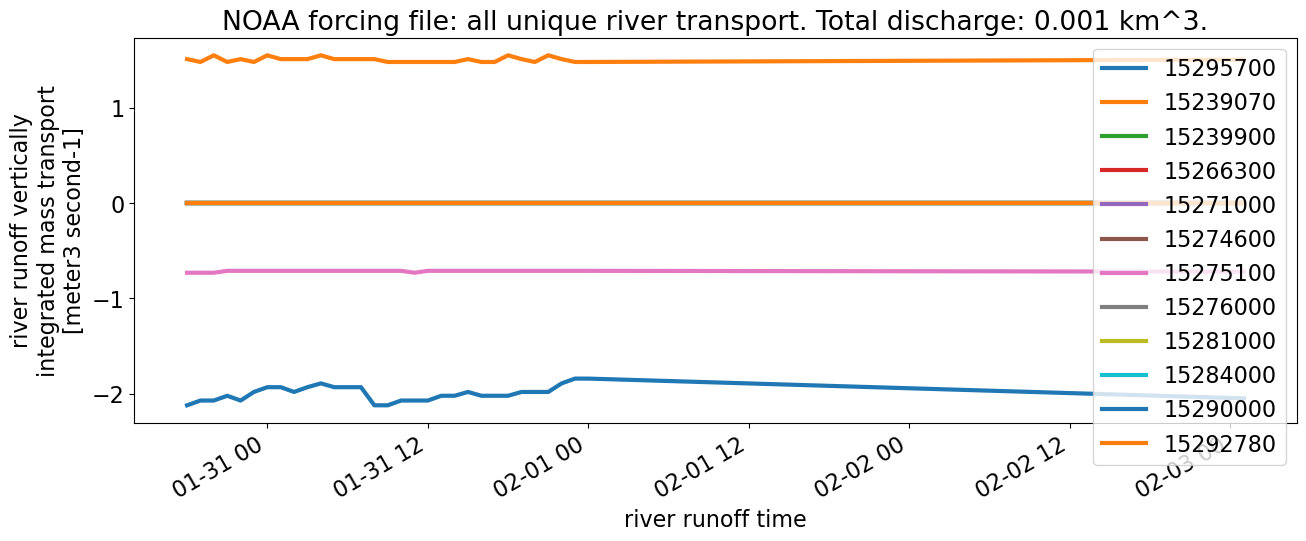
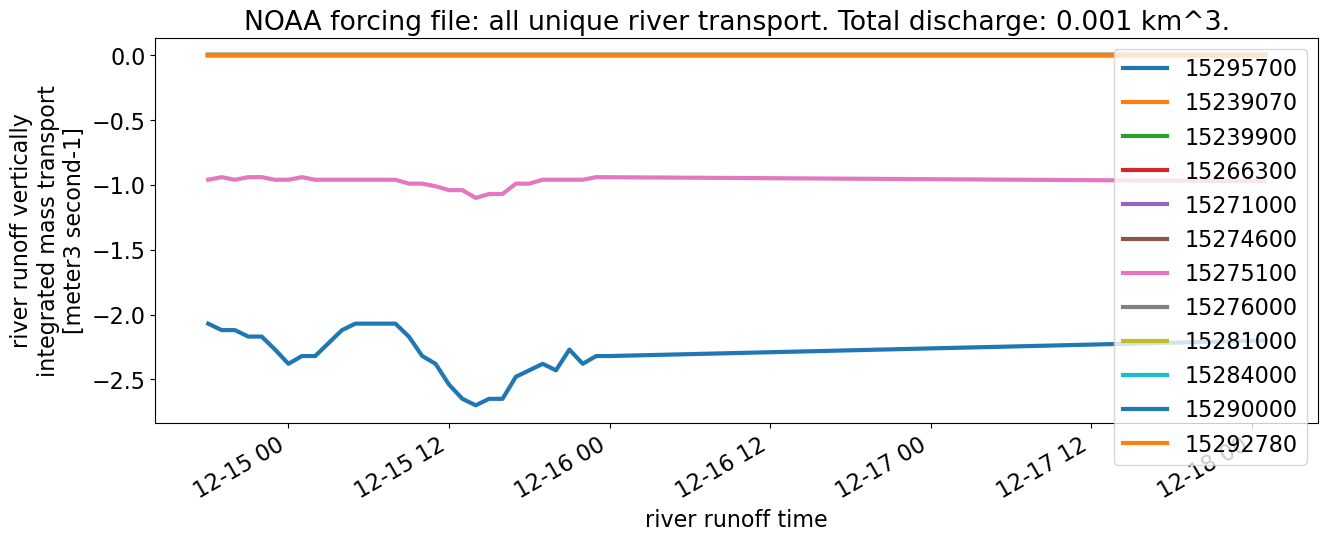
ds["river_transport"].isel(river=unique_inds).plot.line(**kwargs_line, figsize=(15,5));
plt.title(f"NOAA forcing file: all unique river transport. Total discharge: {noaa_discharge} km^3.")
plt.legend(labels)
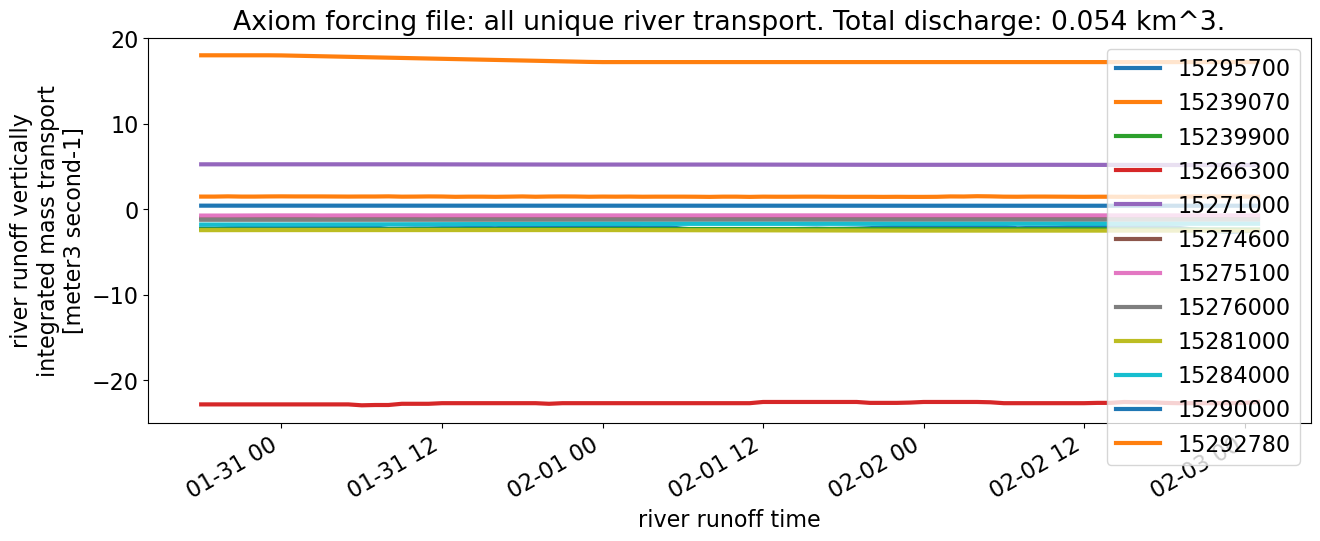
dscompare["river_transport"].isel(river=unique_inds).plot.line(**kwargs_line, figsize=(15,5));
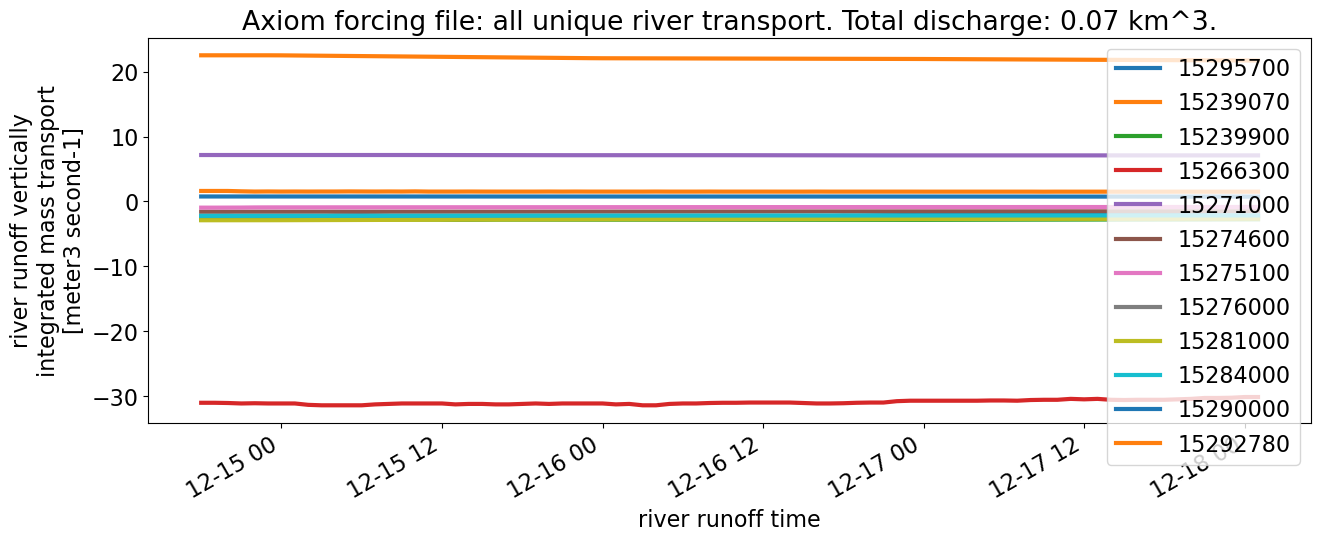
plt.title(f"Axiom forcing file: all unique river transport. Total discharge: {axiom_discharge} km^3.")
plt.legend(labels)
# pull over rivers that have nonzero transport from original file
ibool = abs(ds["river_transport"].sum(dim="river_time")) > 0
ind = ds["river"][ibool] - 1
key = "river_transport"
ds[key].isel(river=ind).plot.line(**kwargs_line, **kwargs_noaa, figsize=(15,7));
dscompare[key].isel(river=ind).plot.line(**kwargs_line, **kwargs_axiom);
plt.legend()
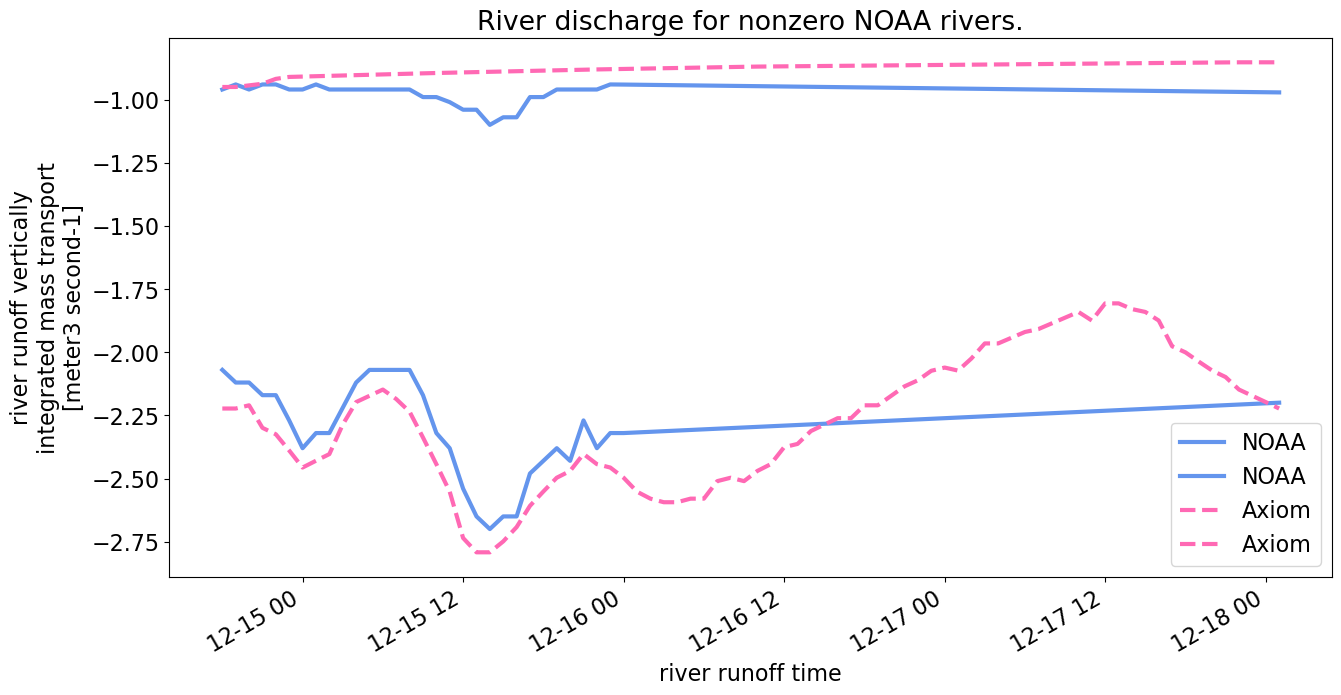
plt.title("River discharge for nonzero NOAA rivers.")
fig, axes = plt.subplots(1, 3, figsize=(15,5))
ds["river_temp"].isel(s_rho=0).plot(ax=axes[0], cbar_kwargs={"label": ""})
dscompare["river_temp"].isel(s_rho=0).plot(ax=axes[1], cbar_kwargs={"label": ""})
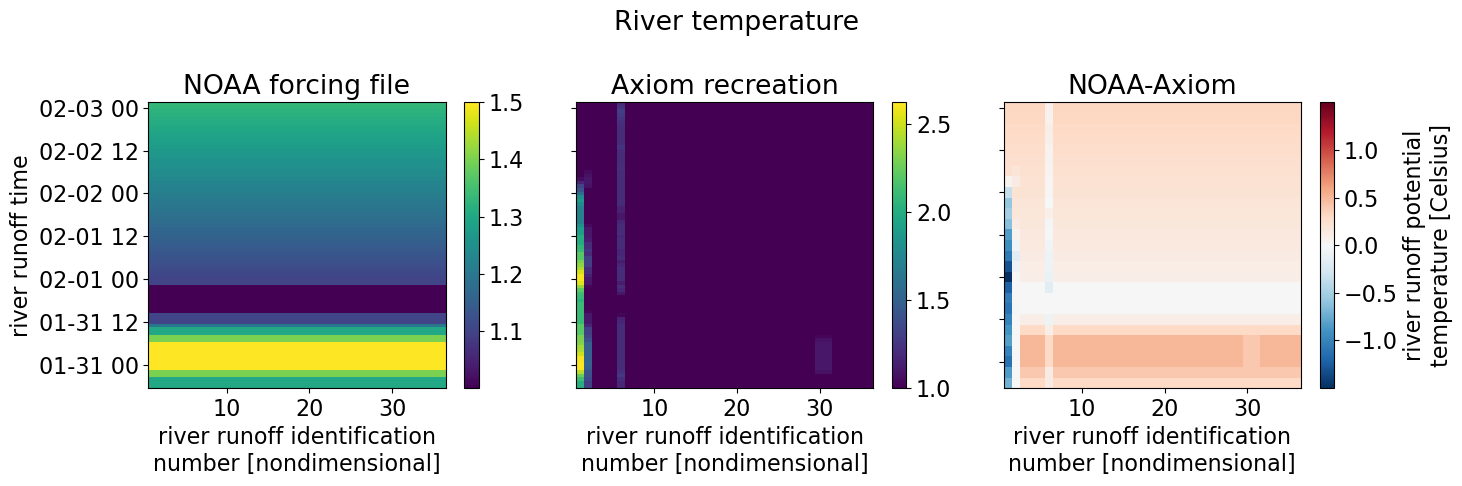
(ds["river_temp"] - dscompare["river_temp"]).isel(s_rho=0).plot(ax=axes[2])
axes[0].set_title("NOAA forcing file")
axes[1].set_title("Axiom recreation")
axes[1].set_ylabel("")
axes[1].set_yticklabels("")
axes[2].set_title("NOAA-Axiom")
axes[2].set_ylabel("")
axes[2].set_yticklabels("")
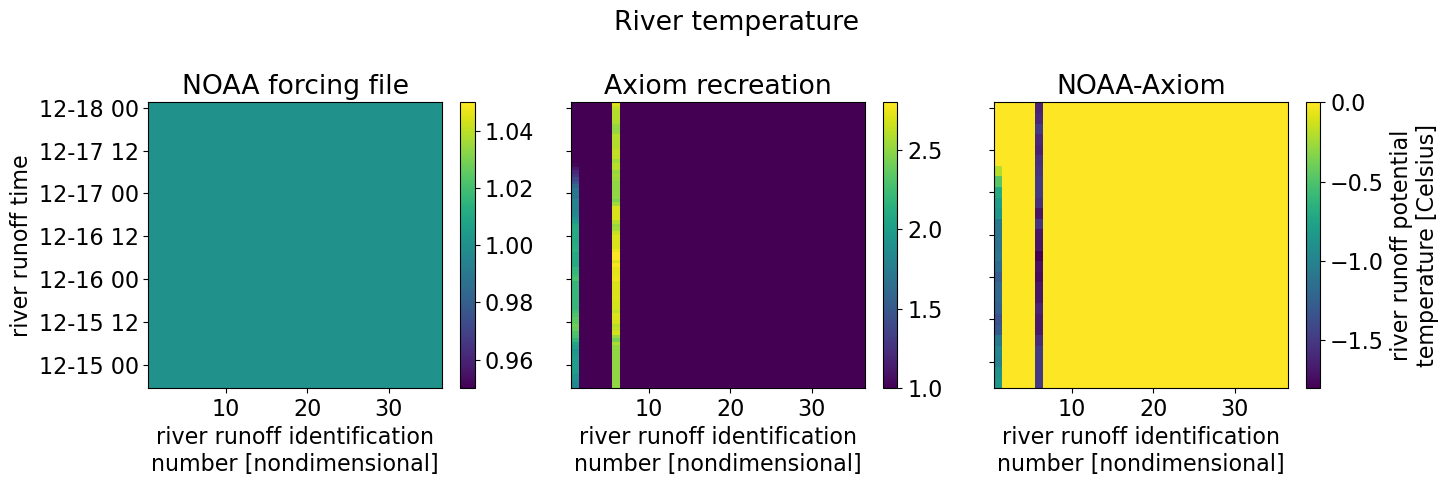
fig.suptitle("River temperature")
plt.tight_layout()
# pull over rivers that have non-one temp from Axiom file
ibool = (dscompare["river_temp"].isel(s_rho=0) > 1).any(dim="river_time")
ind = dscompare["river"][ibool] - 1
key = "river_temp"
ds[key].isel(s_rho=0, river=ind).plot.line(**kwargs_line, **kwargs_noaa, figsize=(15,7));
dscompare[key].isel(s_rho=0, river=ind).plot.line(**kwargs_line, **kwargs_axiom);
plt.legend()
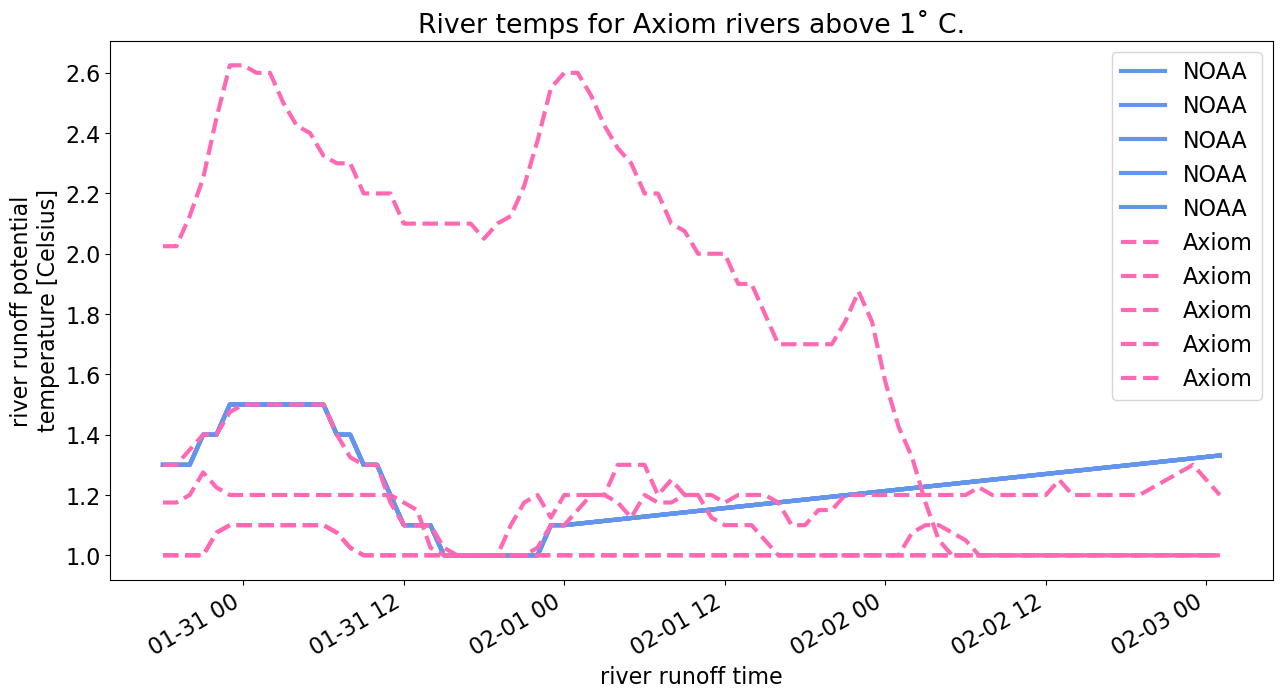
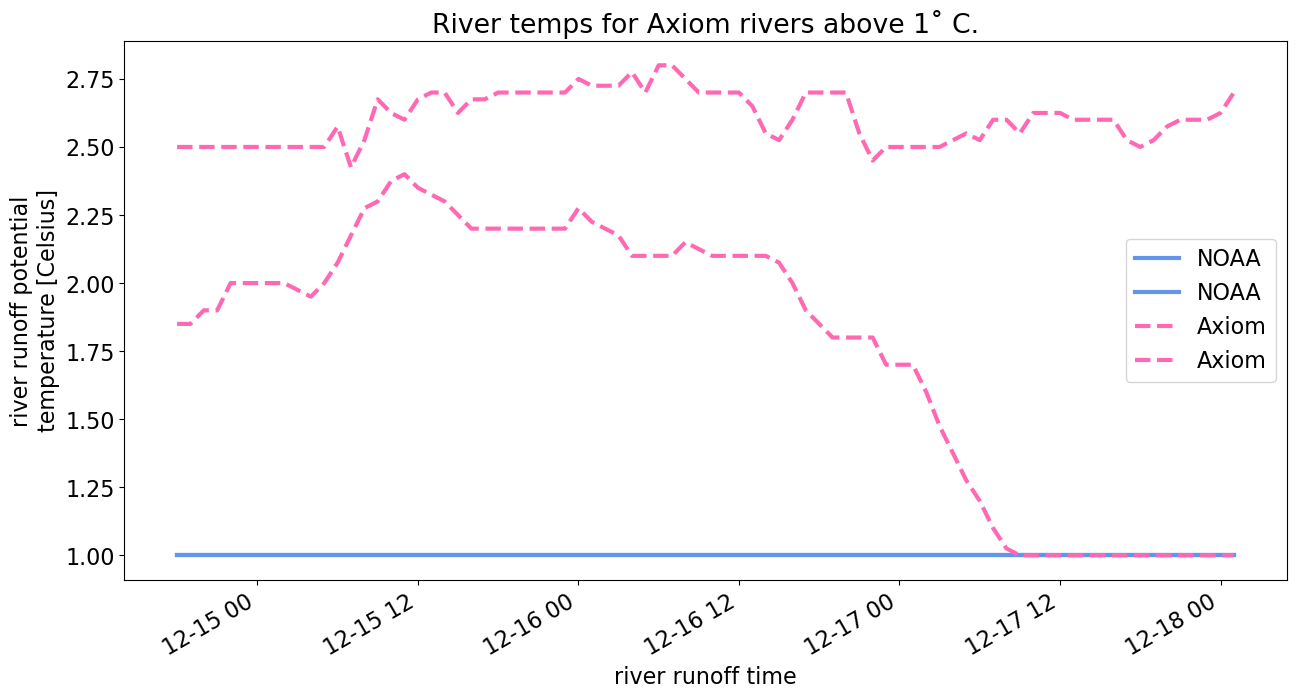
plt.title("River temps for Axiom rivers above 1˚ C.")
December 2022 file#
The total amount of discharge input over the 4 days in the forcing file is much larger from the Axiom file: 0.07 km\(^3\) compared with 0.001 km\(^3\) from the NOAA file. However, for the two rivers that do have discharge from the NOAA file (most are all 0s), we are able to estimate a good match (“River discharge for nonzero NOAA rivers”).
River temperature data is all 1s in the NOAA file but we allow for spatial variation and see in the comparison (“River temps for Axiom rivers above 1 C”) this variation. Note than any temperatures below 1 degree are set to 1 degree.
Show code cell source
loc = f'{chr.PATH_INPUTS_RIVER}/nos.ciofs.river.20221216.t00z.nc'
ds = xr.open_dataset(loc)
start = pd.Timestamp(ds["river_time"].values[0]).strftime("%Y-%m-%dT%H:%MZ")
end = pd.Timestamp(ds["river_time"].values[-1]).strftime("%Y-%m-%dT%H:%MZ")
dscompare = create_river_forcing_file(start, end, ndays=2, window=1)
ds = ds.swap_dims({"time": "river_time"})
dscompare = dscompare.swap_dims({"time": "river_time"})
Show code cell source
plot_comparison(ds, dscompare)

January 2023 file#
For the same reasons previously listed, the discharge is much higher from the Axiom file: 0.06 km\(^3\) compared with 0.001 km\(^3\) from the NOAA file. For the rivers that we estimate in the same way as NOAA, we get similar results.
Show code cell source
loc = f"{chr.PATH_INPUTS_RIVER}/nos.ciofs.river.20230201.t00z.nc"
ds = xr.open_dataset(loc)
start = pd.Timestamp(ds["river_time"].values[0]).strftime("%Y-%m-%dT%H:%MZ")
end = pd.Timestamp(ds["river_time"].values[-1]).strftime("%Y-%m-%dT%H:%MZ")
dscompare = create_river_forcing_file(start, end, ndays=2, window=1)
ds = ds.swap_dims({"time": "river_time"})
dscompare = dscompare.swap_dims({"time": "river_time"})
Show code cell source
plot_comparison(ds, dscompare)